

The first update on the project Traces of Lost Libraries is here!
The initial glimpse of the previous Berlin owners is ready. What has been done so far? I took the first quarter of the rare prints collection – opened every single book and wrote down older shelfmarks, IDs of stamps of Berlin libraries, and German timestamps of stock revisions. I double-checked, added the information to our xlsx file list of rare prints collections, and double-checked again. I believe, such raw data are a good test sample to start playing with.
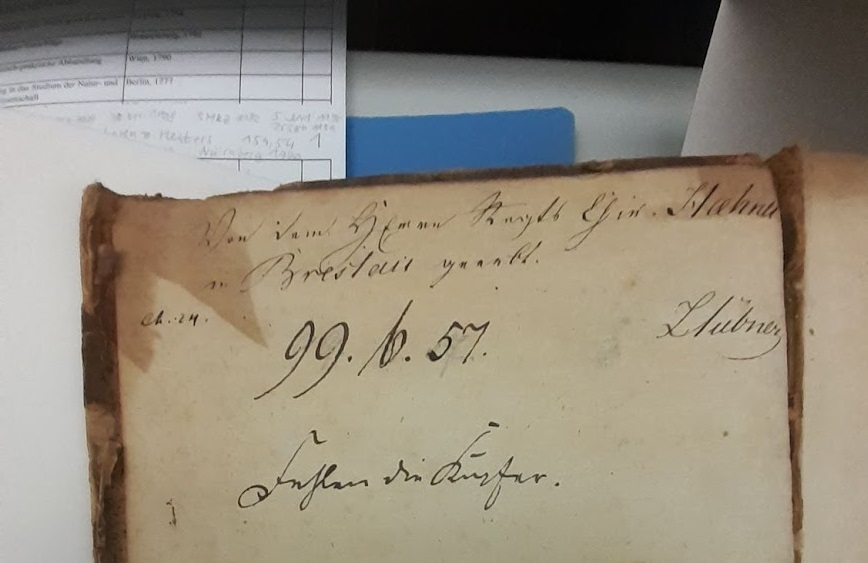
In order to retain as much control over the data as possible, I made a Python script, utilizing of course the Pandas library. Hence, after some wrangling, and further and further cleaning, I can proudly announce the preliminary results: So far, 41% of the rare prints come from the lost Berlin libraries. Meaning those books either have corresponding stamps or their shelfmarks belong to the same Berlin set. Furthermore, the data are now store in separate tables with matching IDs.
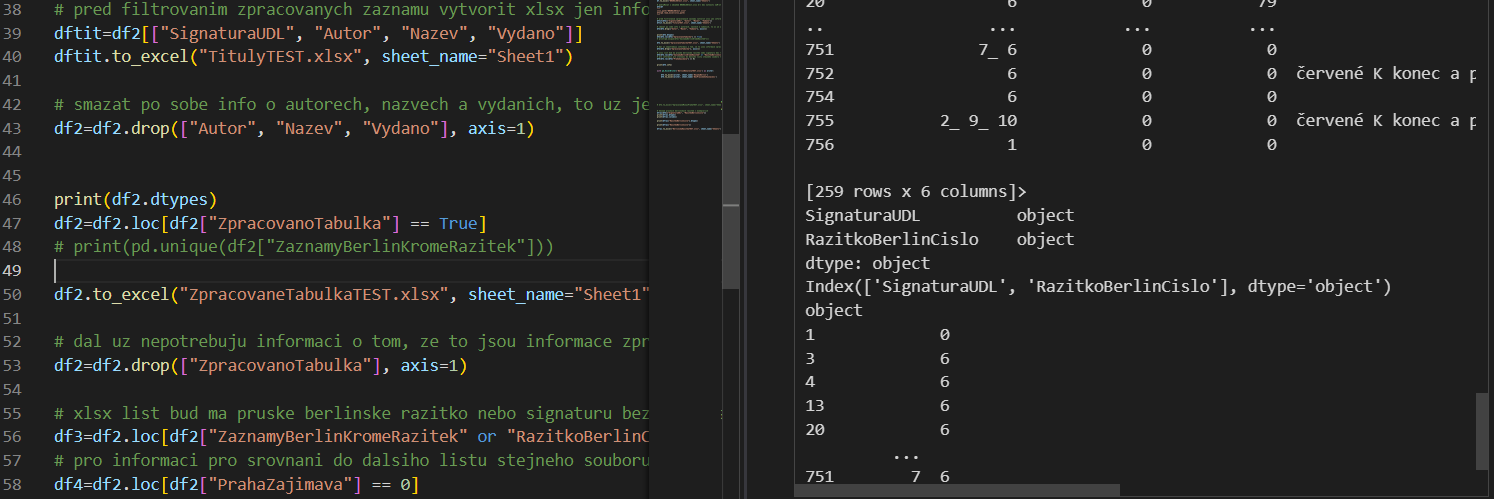
Next steps: Complete the whole raw dataset, re-run the script. After this first automated phase, the old-fashioned research returns once again, I will have to manually check the catalogues of the FWI and of the KWA, confirm that the IDs indeed match, and add the corresponding datasets based on the FWI and KWA library entries.
Then, finally, correlations and timelines for the entries can be made. Reconstruct the missing pieces and visualise which parts of the original Berlin libraries were taken to Prague. For the final touch, it will be easy to fill with detailed already existing catalogue information on the book titles, based on other copies of the books in libraries elsewhere.
Markéta Ivánková
