

Je tu první update k projektu Stopy zaniklých knihoven: Berlín!
Máme první hlubší vhled do geneze vlastnické struktury „berlínské sbírky“ starých lékařských tisků na 1. LF UK. Jak daleko práce postoupila? Vzala jsem první čtvrtinu sbírky – otevřela každou knihu a zapsala starší signatury, ID razítek berlínských knihoven a německá razítka z revizí knihovních fondů. Údaje jsem zkontrolovala, informace přidala do stávajícího xlsx seznamu sbírek vzácných tisků a provedla další kontrolu. Takováto raw data jsou dobrým testovacím vzorkem, a nímž se dá začít experimentovat.
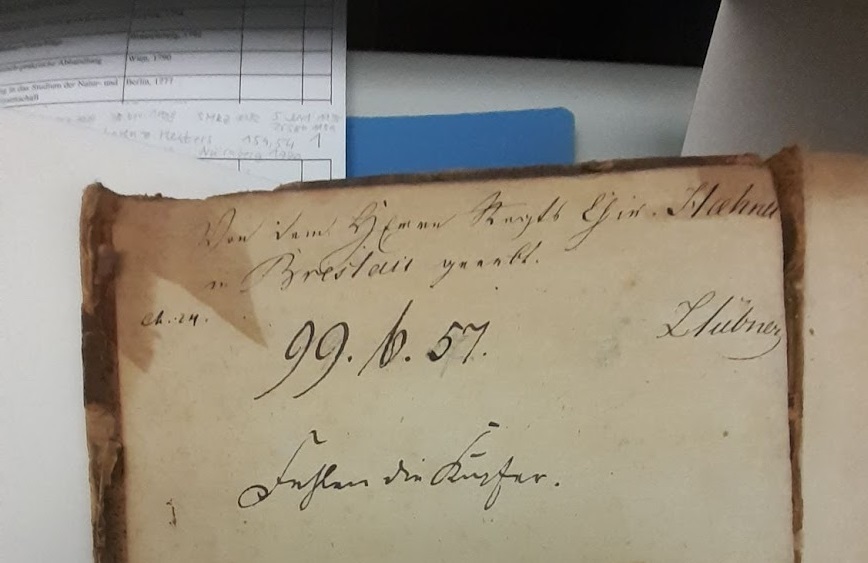
Abych si udržela co největší kontrolu nad daty, napsala jsem skript v Pythonu (a za pomoci knihovny Pandas). Po několikerém čištění a transformaci dat mohu s hrdostí oznámit předběžná zjištění: ze ztracených berlínských knihoven zatím pochází 41 % starých tisků, které jsem zpracovala. To znamená, že knihy splňují podmínku, že obsahují odpovídající razítka hledaných institucí nebo že jejich signatury náleží k témuž berlínskému souboru. Navíc jsou data nyní automaticky uložena v samostatných tabulkách s odpovídajícími identifikátory.
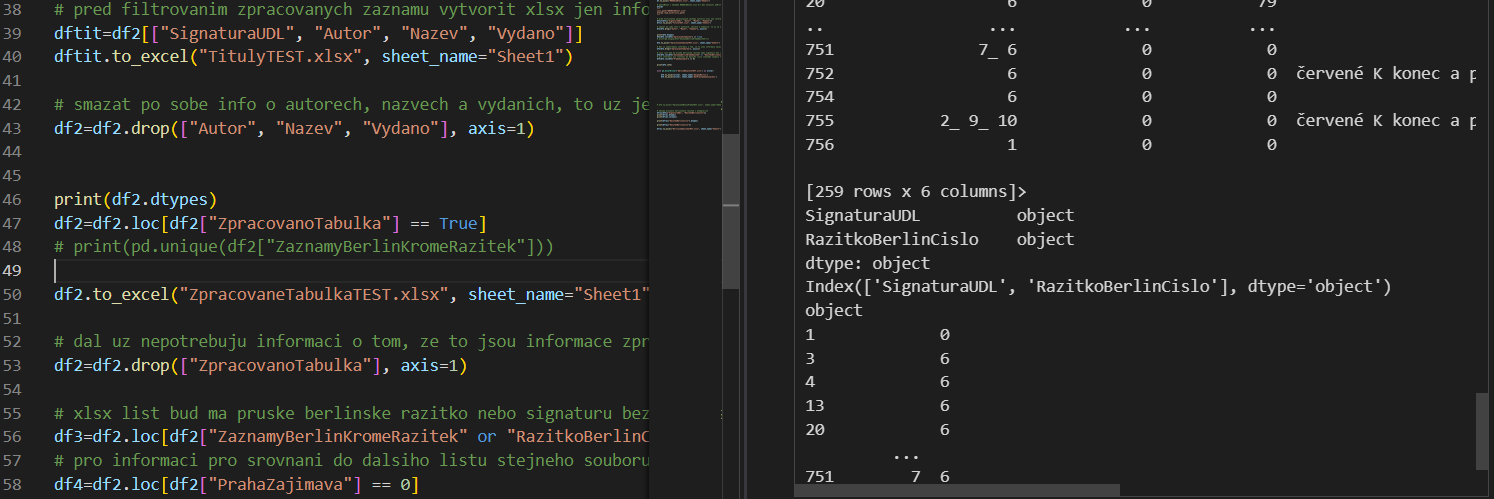
Co dál? Dokončit sběr datasetu a opět spustit skript. Po této první automatizované fázi přijde znovu na řadu tradiční způsob výzkumu, bude nutné ručně zkontrolovat katalogy knihoven FWI a KWA, potvrdit, že ID skutečně odpovídají, a přidat odpovídající nové datasety vytvořené na základě záznamů z FWI a KWA.
Posléze mohu konečně vytvořit časové osy pro jednotlivé exempláře a prověřit korelace v nasbíraných souborech dat. Rekonstruovat chybějící místa a vizualizovat, které části původních berlínských knihoven byly odvezeny do Prahy. Na závěr už bude snadné doplnit podrobné, již existující katalogové informace o názvech knih na základě jiných exemplářů v dalších knihovnách.
Markéta Ivánková
